Optimize GEMM step by step
一步步优化GEMM系列,每次引入一个优化概念并对比性能变化
点击每个标题链接跳转到对应github仓库
总体思路
首先我们构建了一个初级的GEMM kernel,它使用CUDA mma.sync指令来使用GPU tensor core单元,并对比了和cutlass算子的性能
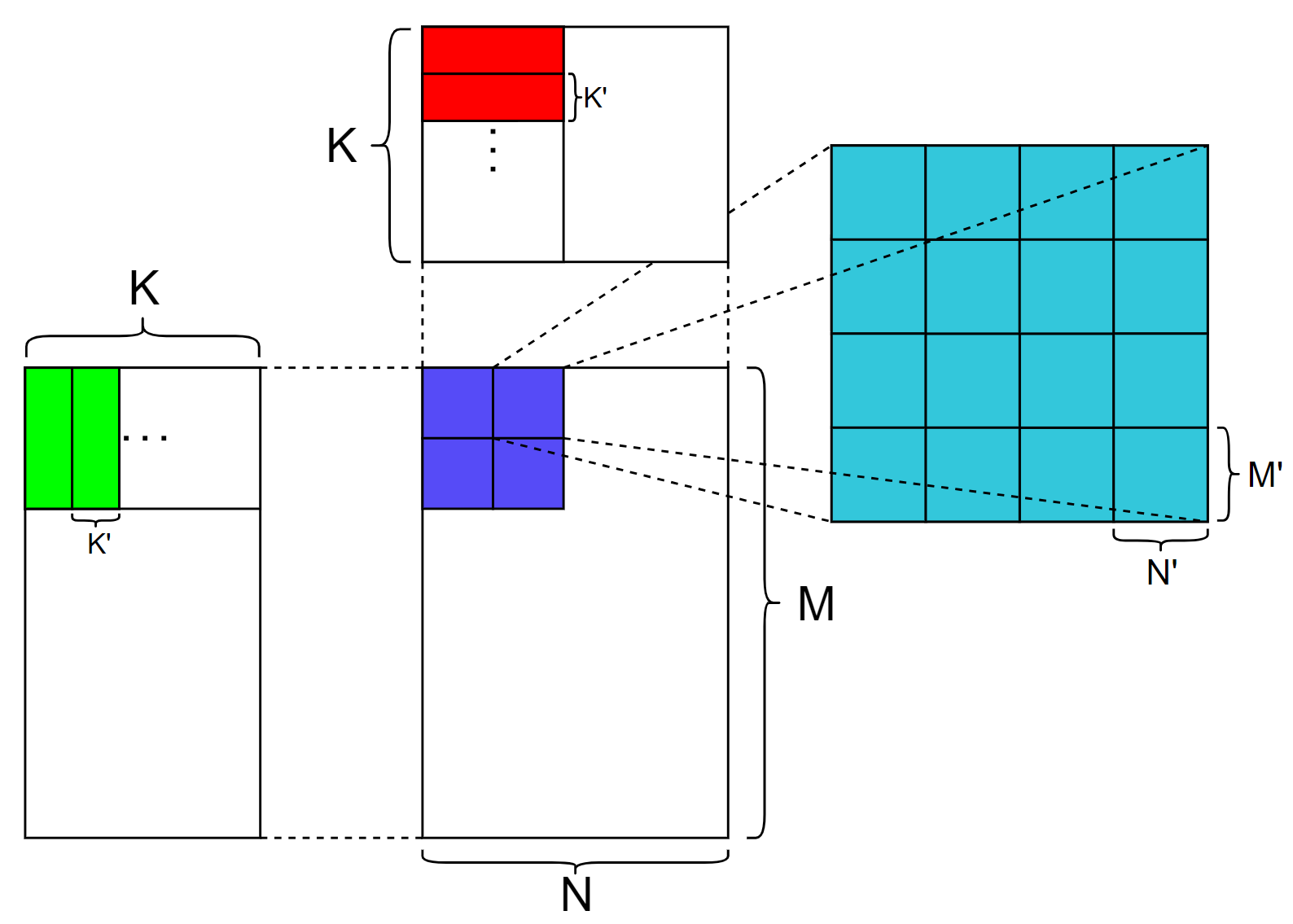
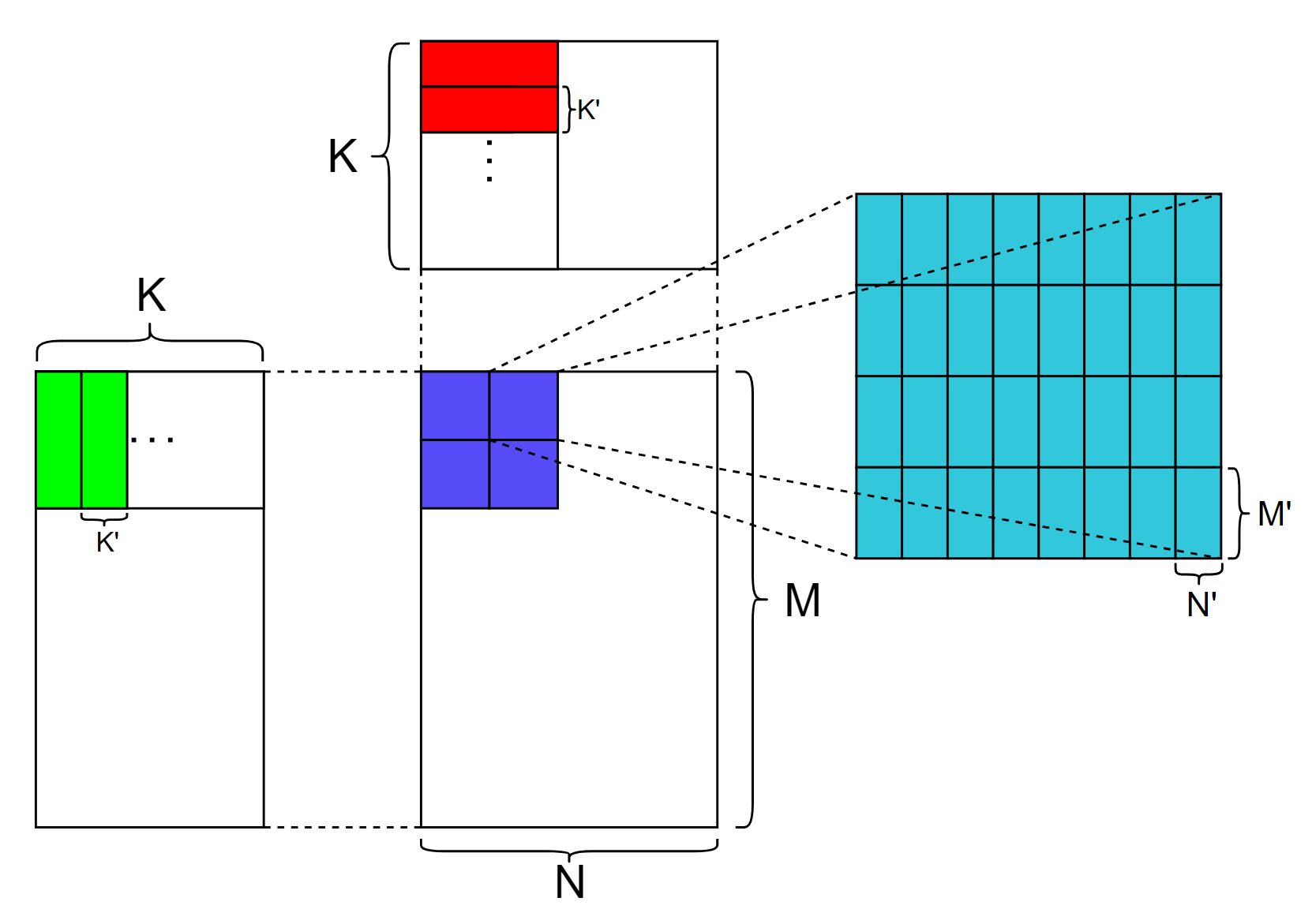
上图展示了GEMM MMA的计算流程,蓝色部分代表1个block要计算的部分,蓝色部分下的每个小方块代表每个warp的计算部分,右侧青色部分代表每个warp的计算部分,青色部分下的每个小方块代表tensor core支持的分块大小,在调用tensor core之前,加载一个绿色方块和红色方块进入共享内存,之后每个warp独立同步地调用mma.sync 来计算每个分块的结果,其中 M'、N' 、K' 代表tensor core单元支持计算的GEMM维度。
baseline性能: 3.44% (相比cutlass)
使用向量化(vector)
vector分支主要介绍向量化load/store,
优化后性能: 4.74%
向量化在不同层级的表现
cu level
1 | *reinterpret_cast<float4*>(&A[tileIdx]) = *reinterpret_cast<float4*>(&arg.A[rowA_0*arg.problem_size.k()+colA_0]); |
ptx level
1 | ld.global.v4.u32 {%r161, %r162, %r163, %r164}, [%rd5]; |
SASS level
1 | LDG.E.128 R8, [R10.64] ; |
结果
1 | [ problem size] (8192,8192,8192) |
避免bank冲突并且合并访存(bfco)
bfco分支主要介绍如何通过解决shared memory bank conflict 和 memory coalesce (访存合并) 来优化性能
优化后性能: 5.00%
Shared memory bank

要注意连续的bank存储连续的字(32-bits),这里字的大小为32 bits,总共有32个bank
要想解决bank conflict问题,要将一个warp内线程读取的shared memory尽量分散到不同的bank里
memory coalesce(访存合并)
访存合并用一句话来简单概括就是一个warp内线程读取的global memory尽量是连续的且128字节对齐
为什么是128字节对齐而不是其他数字?我的理解是cache line的大小是128字节,这样一个warp内的访存可以合并成以cache line为基本单位的memory transaction
代码分析
为了解决bank conflict 和 memory coalesce,对代码做的主要修改为变量 tileidx
1 | // in function loadtileC |
结果
1 | [ problem size] (8192,8192,8192) |
使用异步拷贝(ldgsts)
ldgsts 分支主要来介绍使用Ampere引入的异步拷贝来优化性能
优化后性能: 5.36%
异步拷贝
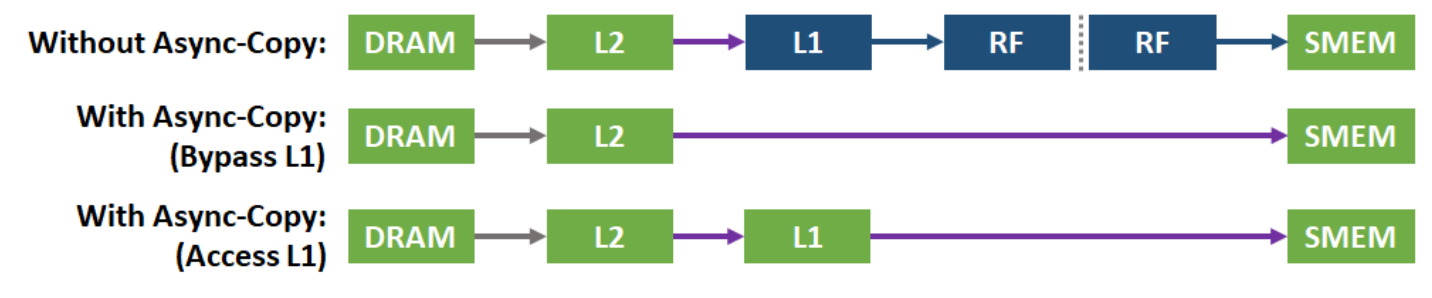
CUDA 11 引入了一个新的async copy(异步拷贝)API来利用 A100 GPU 硬件加速将数据从global memory(全局内存) 直接拷贝到shared memory(共享内存)。异步拷贝会执行从全局内存到共享内存的异步(非阻塞)直接内存传输(旁路SM,也就是不经过寄存器),它将”从全局内存加载数据到寄存器”和”将数据从寄存器写入共享内存”这两个操作结合成单个且高效的操作。
异步拷贝消除了通过寄存器存储中间数据的需要,进而减少了所需的寄存器访问带宽。它有效地利用了存储带宽并且降低了功耗。正如它的名字所表明,异步拷贝是异步完成的,允许其他的计算和从全局内存到共享内存的数据搬运同时发生。异步拷贝通过新的同步特性来通知程序数据搬运的完成。
旁路L1和寄存器可以明显地提升数据拷贝的性能,特别是对于多个连续的异步拷贝操作,这些操作将大量数据从全局内存复制到共享内存。
异步拷贝指令有两个变种,适用于不同的使用场景。BYPASS:旁路掉L1缓存和寄存器,ACCESS:将数据保存到L1以供后续访问和重用。
cu level
1 | asm volatile("cp.async.cg.shared.global [%0], [%1], %2;\n" |
ptx level
1 | cp.async.cg.shared.global [%r158], [%rd18], 16; |
SASS level
1 | LDGSTS.E.BYPASS.128 [R7+0x1800], [R4.64] ; |
结果
1 | [ problem size] (8192,8192,8192) |
使用寄存器(reg)
reg 分支介绍使用寄存器来优化性能
优化后性能: 35.39%
CUDA中的寄存器
寄存器的概念可能对于高级编程者来说是比较陌生的,因为在编程中一般并不会刻意地声明要使用寄存器来做什么操作,编译器会帮我们处理好这个问题,这就导致了在编写CUDA算子时往往会忽略掉寄存器的使用,可以通过ncu或编译时设置编译参数来查看kernel中每个线程使用了几个寄存器,比如在我们对比的cutlass的kernel中每个线程使用了230个寄存器,但是本例中baseline的kernel中每个线程只使用了32个寄存器,所以可以考虑将频繁使用的tileC(也就是图中的蓝色部分)从共享内存转移到寄存器中。
如何使用寄存器?其实很简单,在kernel中声明变量或数组就可以(不过如果一个线程使用太多寄存器会发生register spilling,可以在编译好程序后反汇编查看下有没有local memory)
在代码中添加了
1 | ElementOutput C_fragment[64]; |
并修改好相关逻辑后,再次编译发现每个线程使用了156个线程
杂项
之前方法优化效果不明显的原因应该是kernel性能瓶颈在别的地方,可以从这个寄存器优化后的版本尝试如果不采用向量化,不解决bank冲突或访存不合并,或者不采用异步拷贝,kernel的性能变化是怎样的?
结果
原来没有使用寄存器才是kernel性能差的主要原因…
1 | [ problem size] (8192,8192,8192) |
使用数据预取(prefetch)
prefetch 分支介绍使用数据预取来优化性能
优化后性能:39.36%
数据预取需要将缓冲区加倍,主要流程如下
假设计算mma_{i}依赖于数据data_{i}, load data_{i}代表开始加载数据data_{i}, 只有在synchronize后加载的数据才保证可见, 那么数据预取的伪代码如下
1 | load data_{1} |
这样可以让数据加载(data_{i+1})和计算(mma_{i})尽可能重叠起来
结果
1 | [ problem size] (8192,8192,8192) |
关于PTXAS有趣的发现(ptxas)
ptxas 分支分享一个调优过程中发现的关于ptxas(ptx汇编器)有意思的东西
事情起因
在优化kernel过程中,发现每个warp循环计算每个Ctile时,都需要从共享内存加载Atile和Btile一次,这样Atile和Btile会被重复加载4次,那其实这里数据是可以复用的,而不用多次加载,于是重新设计了下每个warp计算流程,将4x4tile划分为4个2x2的大tile,每次计算大tile前先把对应的Atile和Btile从共享内存加载到寄存器中,在计算下一个大tile时只需要重新加载一个 A/B tile即可(例如从左上角移动到右上角只需要重新加载Btile即可,Atile是可以复用的),下图为优化前后的计算流程图,其中C tile为每个warp需要计算的矩阵C的部分,图上的数字代表数据块被加载的次数
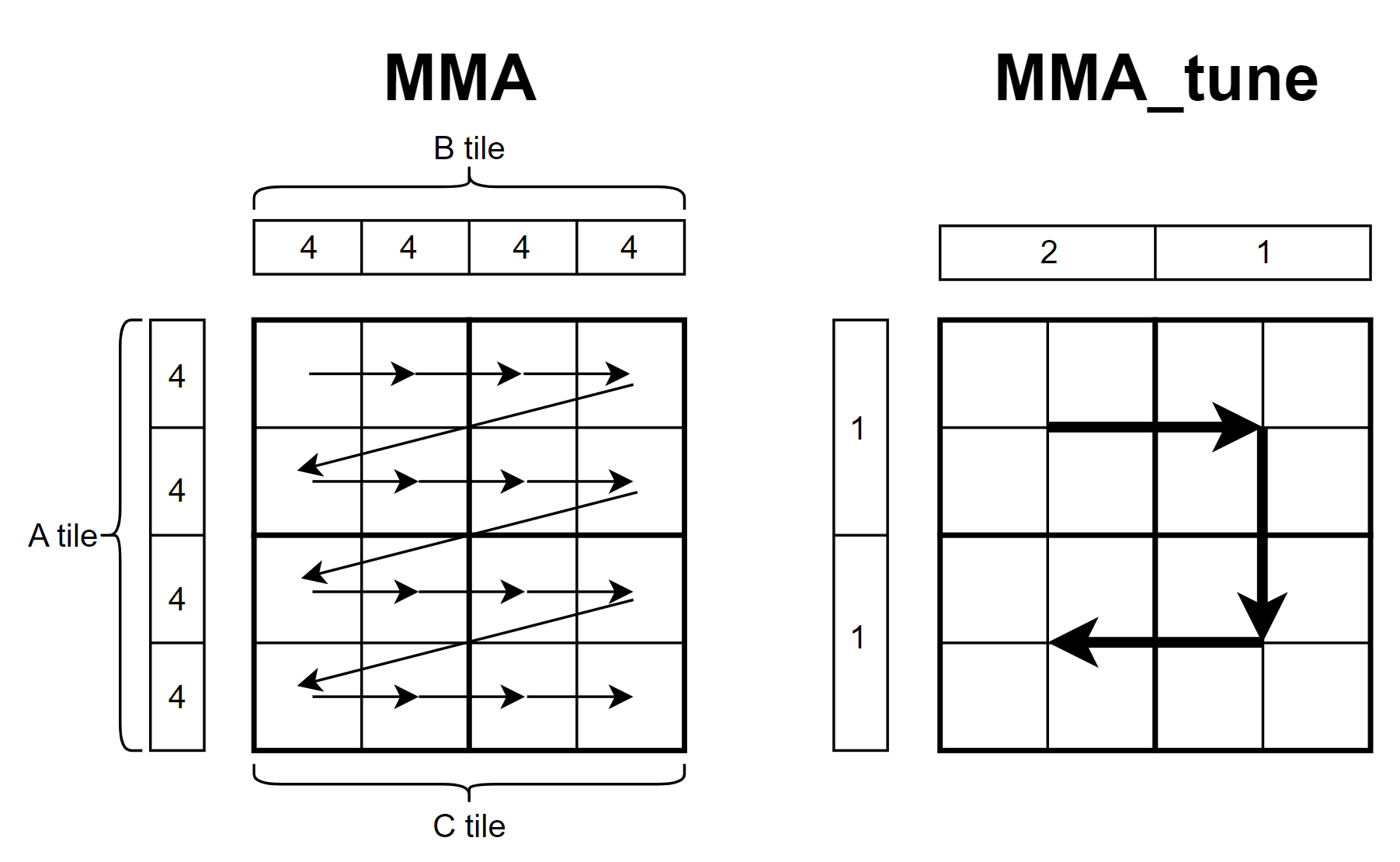
然而就在我把代码写好,验证通过后,惊讶地发现两个kernel的运行时间很接近,通过ncu profile后发现运行的指令数竟然是一样的,反汇编后发现两个kernel的sass指令数竟然是相同的,然后仔细看了下,代码逻辑完全是一模一样的,只是部分寄存器命名不一样,这有点离谱,然后看了下两个kernel的ptx指令逻辑还是不一样的,难道CUDA的ptxas优化的这么离谱。
这里给出kernel的ptx和sass指令
两个kernel的ptx版本分别为 ptx_mma 和 ptx_mma_tune
两个kernel的sass版本分别为 sass_mma 和 sass_mma_tune
杂项
优化了半天最后发现机器码都是一样的,确实感觉到了编译器的强大,关键是怎么知道代码哪些是已经被编译器优化好了呢。
另外意外发现了A100 80GB 相比A100 40GB 可以提升33%左右的性能,于是感觉很奇怪,这两个版本不就是显存大小不一样嘛,怎么运行速度差距这么大,于是发现A100 80GB显存带宽 2TB/s,而40BG版本显存带宽 1.5TB/s,这相当于显存带宽提升了33%,这难道全部转化成性能提升了吗?
1 | A100 40GB |
优化数据预取(prefetchx)
prefetchx 分支和之前的prefetch分支类似,区别是增加了预取数据大小并利用了同步指令cp.async.waitgroup N
优化后性能:46.89%
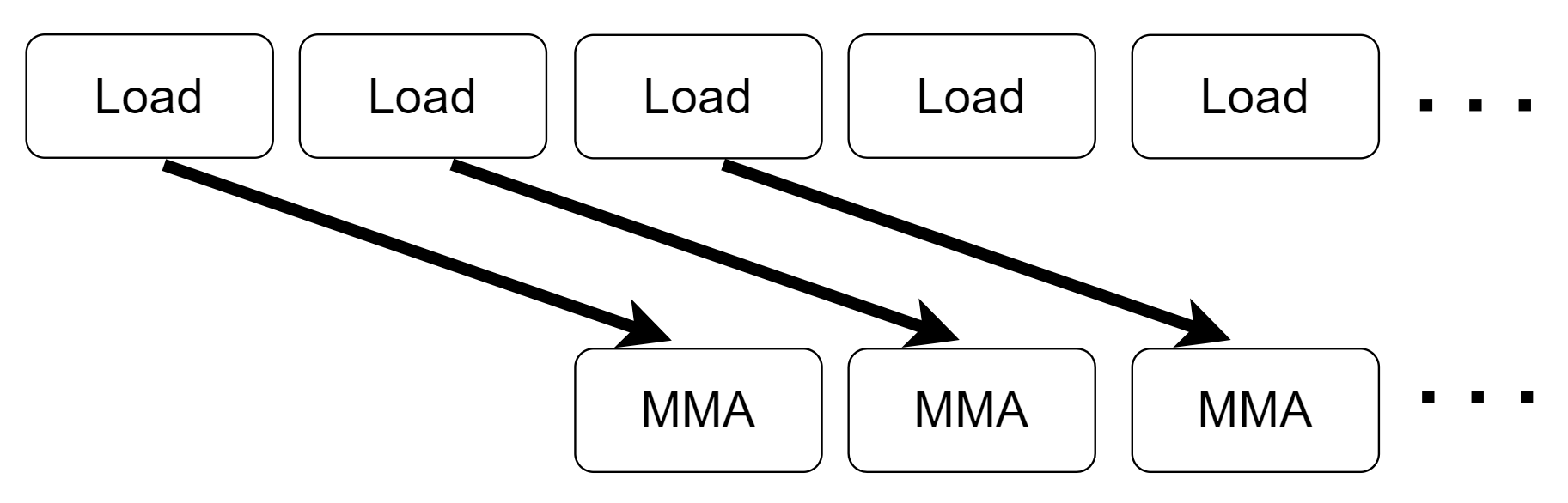
数据预取在之前介绍过,本次优化主要将预取数据的大小增加了1倍,并且显式地调用同步指令cp.async.waitgroup N来确保数据已经拷贝完成,主要流程如下图片
结果
PS: 这次测试结果使用的是A100 80GB版本
1 | [ problem size] (8192,8192,8192) |
调整线程块和warp计算的矩阵大小(shape)
shape 分支调整了每个block和warp计算的矩阵C的大小
优化后性能:62.39%
cutlass 中 ShapeMMAThreadBlock 代表每个线程块计算的矩阵C的大小,而 ShapeMMAWarp 代表每个warp计算的矩阵C的大小
之前手写的 MMA kernel 每个线程块计算 128x64,每个warp计算 64x32,调整后每个线程块计算 128x128,每个warp计算 64x64,这样可以增加数据复用
PS: 实测如果在kernel中申请长度为128的数组,编译器会将其分配到local memory, 所以为了避免这样的情况发生,需要将长度为128的数组分成两个长度为64的数组
结果
PS: 这次测试结果没有对比之前的kernel
1 | [ problem size] (8192,8192,8192) |
调整线程块分配到的计算位置(swizzle)
swizzle 分支调整每个thread block分配到的计算位置来优化性能
优化后性能: 68.43%
swizzle
本次优化思路来自于 cutlass 中 ThreadBlockSwizzle,一开始接触可能比较难以理解这个概念,这个swizzle最核心的就是对于 blockIdx 进行如下变换
1 | blockIdx.x ==> block_idx_x >> log_tile |
看了上面的变换公式,你可能还是一头雾水,其实我们来用一张图来简单说明(log_tile=2), 假如我们启动了一个kernel,它的gridDim为(16,1,1)(即下图中左边的分布),那么经过 swizzle 变换后得到下图中右边的分布,所以我们可以发现 swizzle 后的线程块在2D分布上满足局部性原理,那这样有什么好处呢,好处就是可以尽量提升L2缓存的命中率或L2缓存中的数据复用。
1 | 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 0 4 8 12 |
结果
1 | [ problem size] (8192,8192,8192) |
使用ldmatrix指令
ldmatrix.sync 指令是 Warp-level matrix load instruction,它是 mma.sync 对应的load共享内存的指令
优化后性能: 73.65%
解决shared memory bank冲突
之前没有注意到shared memory 存在 bank 冲突 ,所以通过调整 shared memory 布局来解决 bank 冲突问题
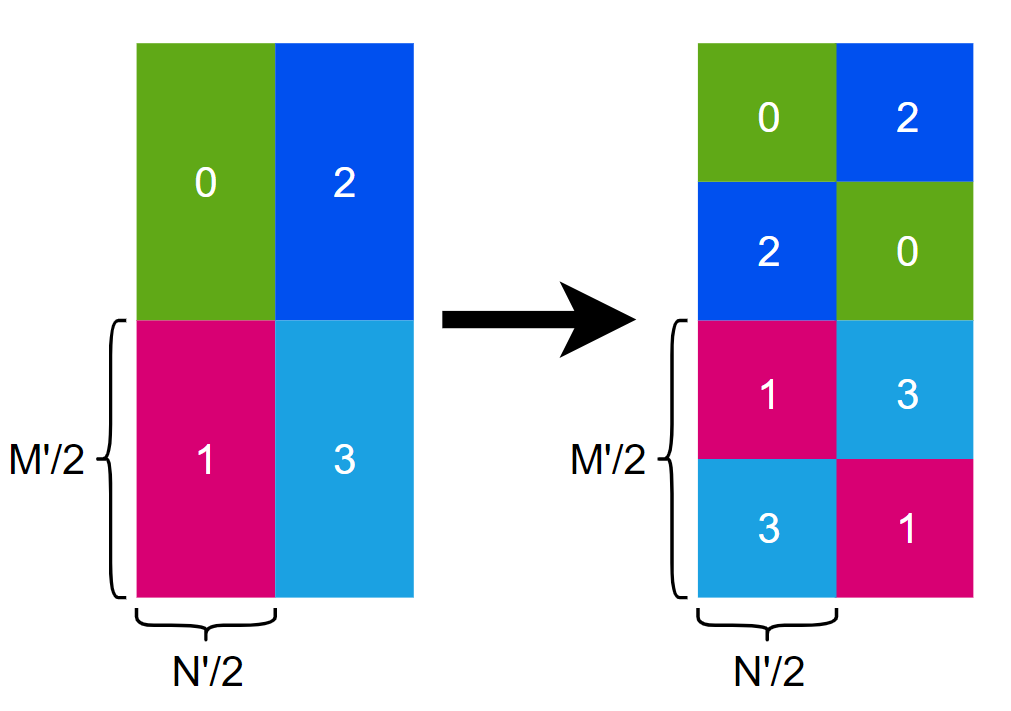
上图中 0,1,2,3 分别代表每个 warp 一次加载的 shared memory 部分, 加载的部分为 A 矩阵(行主序)
访存合并
在解决 shared memory bank 冲突时,如果做如下调整会导致 global memory 访存无法合并
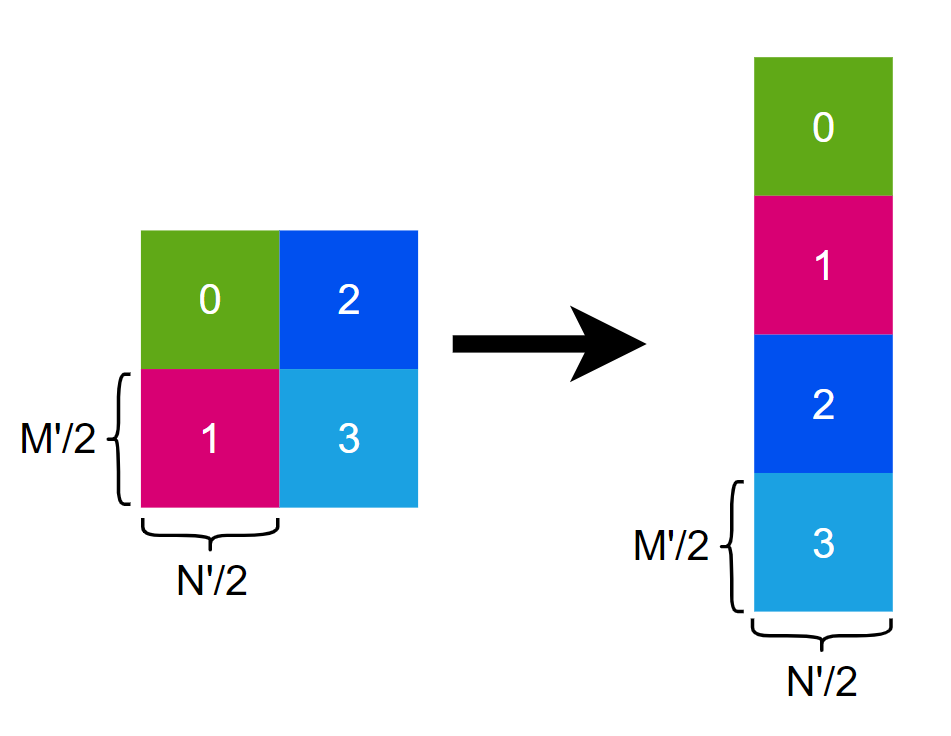
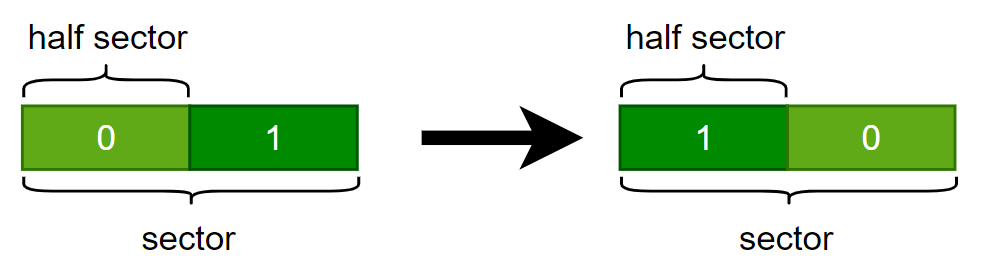
因为 N'=8 , 所以一行正好是 32bytes,即一个sector,而如果一个sector被拆开放到 shared memory 中去会导致访存无法合并,而下图中的变换是可以合并访存的
Nsight Compute
Nsight Compute(ncu) 是 NVIDIA 推出的对 kernel profile 工具,之前一直用的命令行方式,最近发现 ncu-ui 输出的信息更完善丰富,比如下图可以对访存进行细致的展示
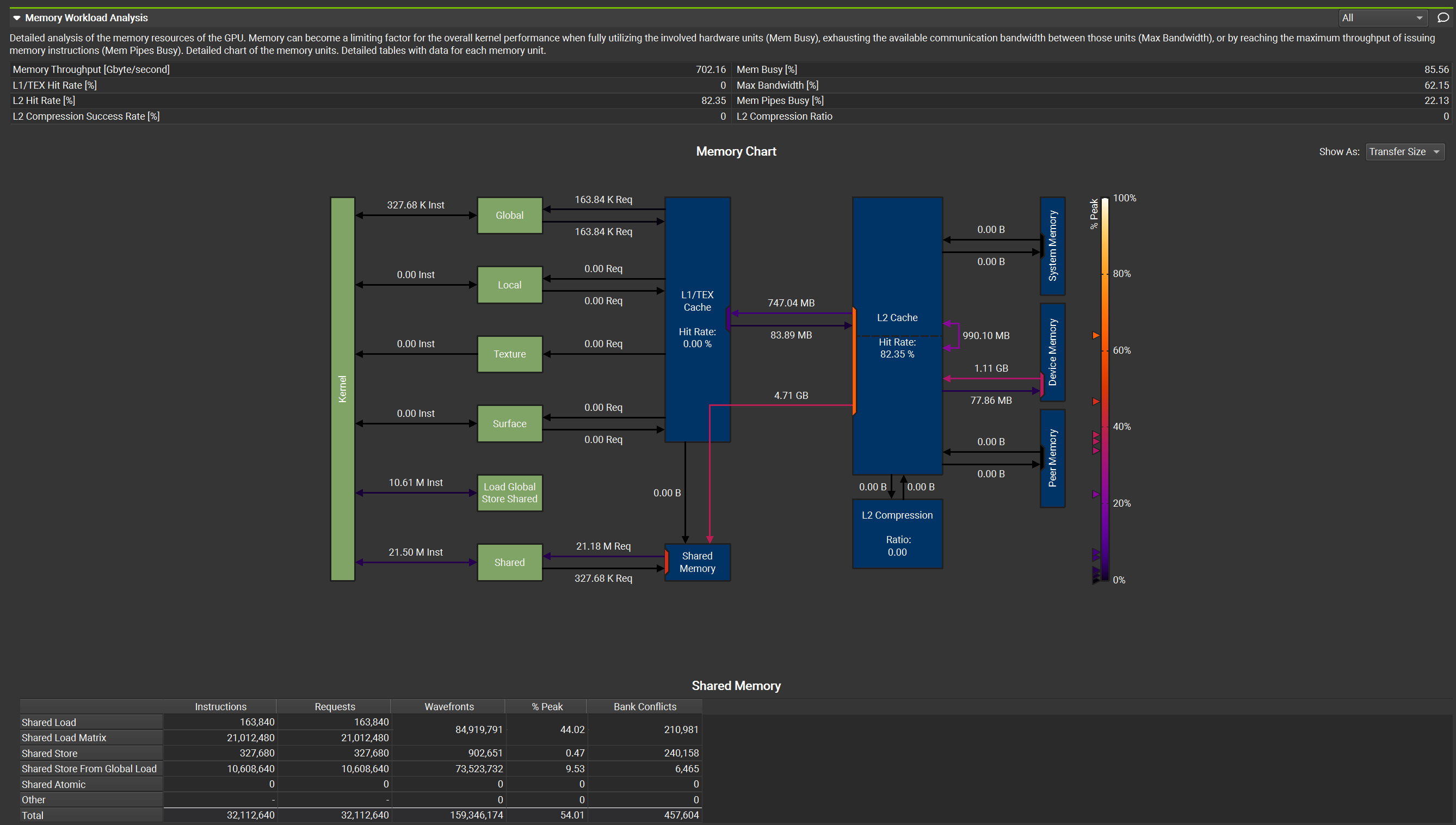
结果
1 | [ problem size] (8192,8192,8192) |
Optimize GEMM step by step