gLLM 推出编码器分离(Encoder-Disaggregation):多模态推理吞吐再上台阶
开源分布式 LLM 推理系统 gLLM 新增「编码器分离」能力,将视觉编码器与语言模型解耦部署,在相同 GPU 预算下显著提升多模态服务的吞吐与延迟表现。
gLLM 推出编码器分离(Encoder-Disaggregation):多模态推理吞吐再上台阶
开源分布式 LLM 推理系统 gLLM 新增「编码器分离」能力,将视觉编码器与语言模型解耦部署,在相同 GPU 预算下显著提升多模态服务的吞吐与延迟表现。
Some unusual but wonderful thinking about LLMs.
Some links about ebooks and tutorials.
This passage is to log miscellaneous tips.
一步步优化GEMM系列,每次引入一个优化概念并对比性能变化
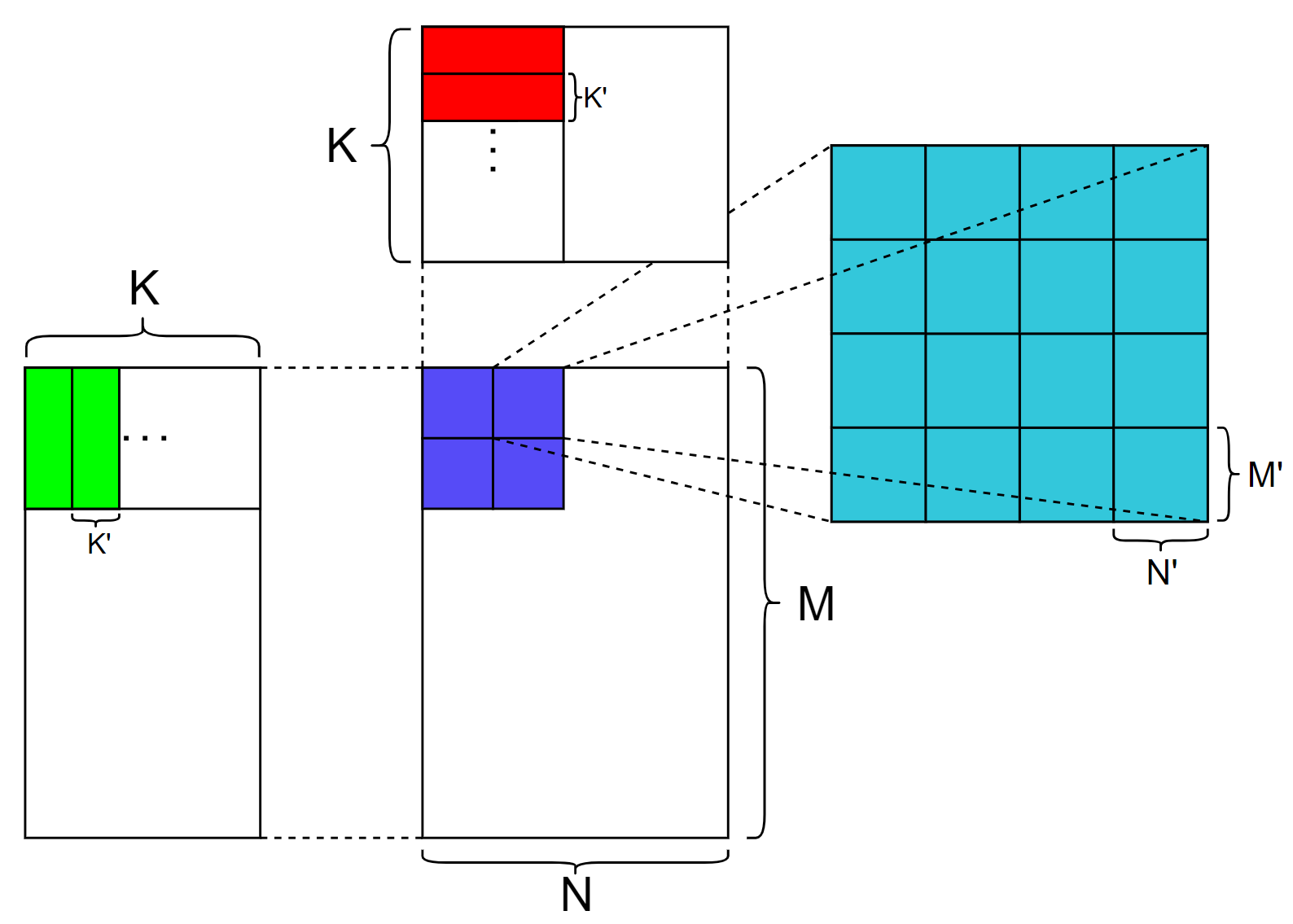
Cutlass use abstract layout to express the mapping rules from logic index to physical index.
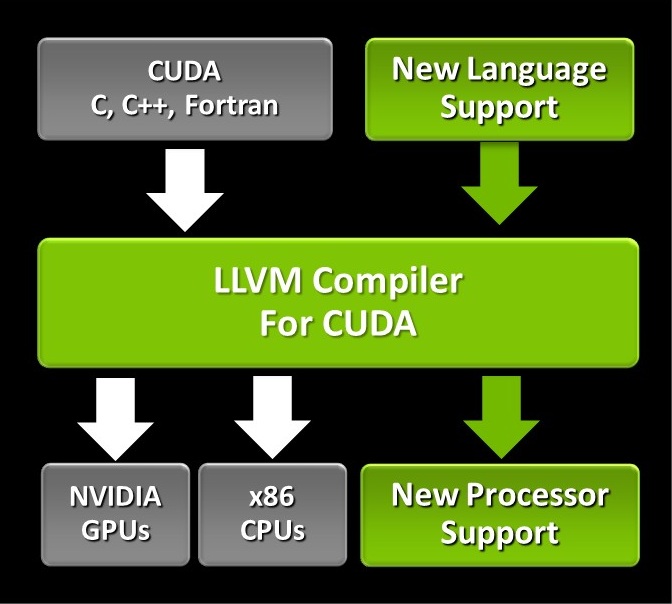
NVIDIA’s CUDA Compiler (NVCC) is based on the widely used LLVM open source compiler infrastructure. Developers can create or extend programming languages with support for GPU acceleration using the NVIDIA Compiler SDK.
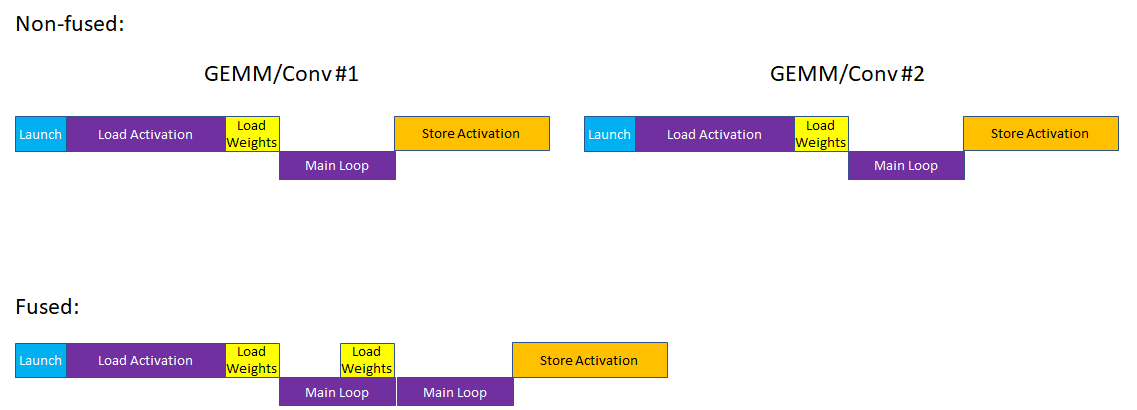
Cutlass examples gives us many examples to learn cutlass. At this time, 13_two_tensor_op_fusion is introduced.
Warp-level GEMMs may be implemented either by TensorCores issuing mma.sync or wmma instructions, or by thread-level matrix computations issued to CUDA cores. Wmma is an API in CUDA C++ for using TensorCores and if you want to use TensorCores by mma.sync you must use ptx by asm.
I always wonder why cutlass provides many kinds of implementions of GEMM instead of just only one. In my opinion, in different situations the best implementions of GEMM differs. So that is what differs cutlass from cublas. You can make your own custiomlized implemention of GEMM to provide the best performance.
In cutlass 3.0, it introduces a new library, Cute, to describe and manipulate tensors of threads and data.
learn cutlass is a series of tutorials to learn cutlass by reading its examples or source code
CUTLASS is a header-only template library. After reading that, you will be lost in templates.
This web is building by Hexo and Icarus.