gLLM 推出编码器分离(Encoder-Disaggregation):多模态推理吞吐再上台阶
开源分布式 LLM 推理系统 gLLM 新增「编码器分离」能力,将视觉编码器与语言模型解耦部署,在相同 GPU 预算下显著提升多模态服务的吞吐与延迟表现。
背景
gLLM 最早起源于 SC’25 论文 《gLLM: Global Balanced Pipeline Parallelism System for Distributed LLM Serving with Token Throttling》 的实现,此后持续迭代演进,逐步发展为一个完整的分布式 LLM 推理引擎。如今它已集成 continuous batching、paged attention、chunked prefill、prefix caching、CUDA Graph、流水线/张量/专家并行等主流特性,对标 vLLM、SGLang 等引擎,并支持 Qwen3.5(Dense 与 MoE、GDN+全注意力混合架构、视觉语言、FP8) 等最新模型。
在多模态(VLM)场景下,一次请求要先经过 视觉编码器(ViT) 把图像编码为 embedding,再交给 语言模型(LM) 做生成。两者算力特征截然不同:编码器是一次性、突发的重计算;语言模型是长尾、逐 token 的自回归解码。当它们挤在同一组 GPU、同一调度循环里时,编码阶段会周期性地“抢占”解码算力,拉高 TTFT、压低整体吞吐。
新功能:编码器分离
这一能力正是 gLLM 对论文 RServe 《RServe: Overlapping Encoding and Prefill for Efficient LMM Inference》 的工程落地:gLLM 已将 RServe 的编码器/语言模型解耦与「编码-prefill 重叠」调度思想完整实现到引擎中。
最新的 编码器分离(E 分离) 把视觉塔单独拆成 Encoder 进程,与 LM 进程 分别部署在不同 GPU 上,二者通过轻量控制面 + 高效数据面协同:
- 控制面:基于 ZMQ 的
DiscoveryServer服务注册与发现,DisaggCoordinator负责请求准入、派发与事件广播; - 数据面:编码器算完的视觉 embedding 通过 NIXL 直接写入 LM 端的显存槽位,避免反复经 CPU 中转;
- 可靠性:内置看门狗(watchdog)对编码任务做超时重派;对不可恢复的失败与客户端中止,引入 abort 事件通道 让各 TP rank 的调度器与协调器一致地回收页表 / SSM 槽位 / NIXL 槽位,杜绝资源泄漏与“卡死”。
这样,编码与解码各自独占算力、互不干扰,多模态服务在高并发下更稳、更快。
性能实测
我们在 Qwen3.5-35B-A3B(MoE,混合 GDN + 全注意力,多模态)上做了一组对照实验:
- 工作负载:每请求随机 1-8 张 720p 图片,输出 128 token;
- 并发扫描:max-concurrency 从 1 扫到 32;
- 统一客户端:所有配置都用同一套 OpenAI 兼容压测客户端,保证公平;
- 对照配置(均为 2 卡预算):
- gLLM 单体 TP2 / gLLM 编码器分离(LM TP1 + Encoder×1)
- sglang 单体 TP2 / sglang 编码器分离(
zmq_to_scheduler)
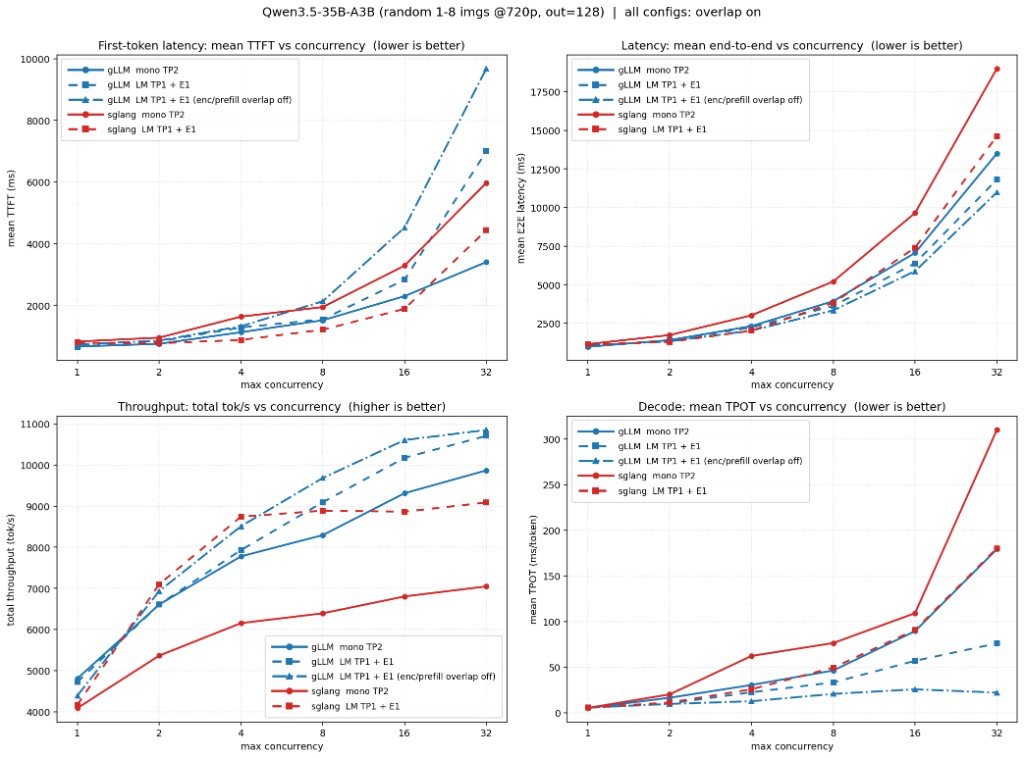
关键结论
- 单体 vs 单体,gLLM 全程领先:在全部并发档位上,gLLM 单体的总 token 吞吐都稳定高于 sglang 单体,且优势随并发升高而扩大。高并发(c=32)时 **gLLM 单体相较 sglang 单体高约 40%**;
- 分离进一步提升吞吐:把编码器拆出去后,两个引擎的吞吐都在高负载下更上一层楼:**gLLM 分离较自身单体 +8.5%,sglang 分离较自身单体 +28.9%**(编码器独占一卡的收益);
- 分离 vs 分离,gLLM 高并发反超:在中低并发(c≈2-4)档位上,sglang 的编码器分离配置(LM TP1 + E1)反而短暂领先;但进入高并发后 gLLM 全面反超。c=32 时 **gLLM 编码器分离的总吞吐较 sglang 编码器分离高约 17.8%**,并取得本次最高的总吞吐 ~10,700 tok/s;
- 端到端延迟更优:尽管分离引入了一次跨卡传输,gLLM 编码器分离凭借更高的吞吐更快清空解码队列,在 c=32 的平均端到端延迟反而最低(约 11.8s),优于 sglang 的各项配置;
- 解码更稳(TPOT 更低):在解码逐 token 延迟(平均 TPOT)上,编码器分离把视觉编码搬离 LM 卡,解码不再被编码计算周期性打断。c=32 时 gLLM 编码器分离仅 76 ms/token,约为 gLLM 单体(179)的一半,更远低于 sglang 单体(310)与 sglang 分离(181)。若进一步关闭「编码-prefill 重叠」,prefill 全部前置、解码阶段完全不受 prefill 干扰,TPOT 可低至 ~22 ms/token 且几乎不随并发上升(代价依旧是 TTFT,见下方消融);
- 关闭「编码-prefill 重叠」吞吐再小幅上探:图中蓝色点划线为 gLLM 分离关闭该重叠后的结果,总吞吐与端到端延迟反而略优于开启时(c=32:10,850 vs 10,707 tok/s、E2E 10.98s vs 11.81s)。原因在于:开启重叠时,针对单个含多图的请求,一收齐元信息就被准入、prefill 随该请求自身的 embedding 到达按图像逐块推进,于是同一请求的 prefill 被拆成多次较小的前向(更小的 GEMM、更多 kernel 启动、对不断增长的前缀重复做注意力),单位算力效率略低;关闭重叠则等所有视觉 embedding 到齐后一次性整段 prefill,计算最紧凑、吞吐与端到端延迟最优。但代价是首 token 要等编码全部完成,TTFT 明显变差(见下方消融)。换言之,这正是一组「首 token 延迟 ↔ 吞吐/端到端延迟」的权衡。
| 配置(c=32) | 总吞吐 (tok/s) | 输出吞吐 (tok/s) | 平均端到端延迟 (ms) | 平均 TPOT (ms/token) |
|---|---|---|---|---|
| gLLM 单体 TP2 | 9,868 | 154.8 | 13,496 | 179.4 |
| gLLM 编码器分离 | 10,707 | 168.0 | 11,806 | 76.2 |
| gLLM 编码器分离(重叠 off) | 10,850 | 170.2 | 10,978 | 22.3 |
| sglang 单体 TP2 | 7,048 | 110.6 | 18,988 | 310.1 |
| sglang 编码器分离 | 9,087 | 142.6 | 14,618 | 180.5 |
说明:除特别标注的「重叠 off」一行外,所有配置均在统一的 2 卡预算、开启 overlap scheduling 的默认设置下测得,为严格同口径对比。
消融实验:编码-prefill 重叠
编码-prefill 重叠是 RServe 的核心机制,作用范围是单个请求内部:对于一条含多张图像的请求,无需等待该请求全部视觉 embedding 编码完成。请求一旦收齐各图像的元信息即可被准入,prefill 在「两层门控」下随这条请求自身的 embedding 陆续到达而逐项推进,从而把同一请求中后续图像的编码与已到达部分的 prefill 在时间上重叠起来。我们在 gLLM 编码器分离上对该机制做了开/关消融(其余设置不变),其 平均 TTFT(首 token 延迟) 对比可直接对照上方主图左上角的 TTFT 子图(图例中的 enc/prefill overlap 即「编码-prefill 重叠」):
| 并发 | 重叠 ON:平均 TTFT | 重叠 OFF:平均 TTFT | TTFT 改善 |
|---|---|---|---|
| 8 | 1,546 ms | 2,130 ms | -27% |
| 16 | 2,828 ms | 4,524 ms | -37% |
| 32 | 6,998 ms | 9,679 ms | -28% |
从图中可以读出三点:
- 重叠是一项面向 TTFT 的优化,效果显著。 对比 gLLM 编码器分离的开(蓝色虚线)与关(蓝色点划线),开启重叠在中高并发把平均 TTFT 降低约 **27%-37%**;这与 RServe 的设计目标完全一致。代价仅是总吞吐略降 1%-6%(重叠把 prefill 按图像逐项分块,略逊于“等齐后一次性 prefill”的吞吐效率,见前文吞吐对比)。
- TTFT 与吞吐/端到端延迟是一组权衡。 gLLM 编码器分离把算力压满以追求更高吞吐和更低端到端延迟(见主图),其首 token 延迟在极高并发处相应抬升;而 sglang 编码器分离(红色虚线)走的是另一条路线:首 token 延迟最为平缓,但吞吐与端到端延迟均不及 gLLM。两者各有侧重,可按业务对“首字快”还是“整体快/省卡”的偏好选型。
- 重叠让分离方案的 TTFT 保持可控。 若关闭重叠,gLLM 分离的 TTFT 会随并发迅速恶化(c=32 达 ~9.7s);正是这一机制把它压回 ~7.0s 并换来吞吐与端到端延迟的领先。若业务更在意首 token 延迟,可通过
GLLM_DISAGG_OVERLAP=1开启该重叠。
如何使用
编码器分离涉及三个入口:
1 | # 1) 服务发现 |
启动后即可像普通 OpenAI 兼容服务一样访问 LM 端口(:8100)。
附录:测试代码与复现步骤
以下命令中
$MODEL为模型目录,$DISC为服务发现地址(如127.0.0.1:9540);python请使用对应引擎(gLLM / sglang)所在环境的解释器。
1. 四种配置的启动命令(均为 2 卡预算)
1 | # (A) gLLM 单体 TP2 |
2. 并发压测命令
所有配置都通过同一套 sglang.bench_serving(OpenAI 兼容客户端)驱动,工作负载(数据集 / seed / 长度)完全一致,只在 --max-concurrency 上沿 1,2,4,8,16,32 扫描,确保公平。单次压测的关键命令如下($C 为并发档位,$N 为该档位的请求数):
1 | python -m sglang.bench_serving \ |
gLLM 配置用
:8100,sglang 配置用:8500。请求数随并发线性放大并做上下限钳制:$N = clamp(6 × $C, 24, 128)(高并发统计更稳、低并发墙钟时间可控);--request-rate inf表示不限速,因此并发是唯一的负载旋钮。每次运行取结果 JSONL 的最后一行(含 bench_serving 的完整指标)汇总绘图。
3. 单请求「编码-prefill 重叠」(gLLM 方法)
本文消融实验对比了该机制的开/关。这是 gLLM 特有的开关:由 LM 进程的环境变量 GLLM_DISAGG_OVERLAP 控制,默认 0(关闭)。LM 会等单个请求的全部视觉 embedding 到齐后再一次性整段 prefill(即消融中的「重叠 off」配置)。设为 1 可开启重叠:请求收齐元信息后即可准入,prefill 随该请求自身的 embedding 陆续到达而逐项推进。
1 | # 默认即为关闭;若需开启单请求重叠,在 lm_server 前加 GLLM_DISAGG_OVERLAP=1 |
注意:该开关只影响单个请求内部的编码/prefill 重叠;跨请求的流水线(LM 处理请求 A 的同时编码器处理请求 B)是两平面设计固有的,不受此开关影响。
结语
编码器分离让 gLLM 在多模态服务中把“编码”与“解码”两类异构负载解耦,在相同硬件预算下取得了更高吞吐与更稳延迟。欢迎到 github.com/gty111/gLLM 体验最新功能。
测试环境:8×140GB GPU 节点;模型 Qwen3.5-35B-A3B(bf16);压测工具为统一的 OpenAI 兼容客户端。
版本信息:SGLang v0.5.9;gLLM commit 75ff6cd。
gLLM 推出编码器分离(Encoder-Disaggregation):多模态推理吞吐再上台阶
https://gty111.github.io/2026/06/13/gllm-encoder-disaggregation/